MapReduce Quick Start
MapReduce Quick Start
AlexMapReduce Quick Start
- 实例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH_1="/The_Man_of_Property.txt"
OUTPUT_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py - 参数说明:
- input : 指定作业的输入文件的HDFS路径,支持使用*统配符,支持指定多个文件或目录,可多次使用
- output : 指定作业的输出文件的HDFS路径,路径必须不存在,并且具备执行作业用户有创建目录的权限,只能使用一次
- mapper : 自己写的执行脚本
- reducer:非必须,如简单过滤就不需要
- file : 本地代码分发上去,适合小文件、本地文件
- 打包文件到提交的作用中,
- 1、map和reduce的执行文件
- 2、map和reduce要用输入的文件,如 配置文件
- 类似的配置还有
-cachefile(具体文件)/-cacheArchive(可能是一个目录,包含目录所有文件)分别用于向计算节点分发HDFS文件和HDFS压缩文件
- 打包文件到提交的作用中,
- jobconf : 制定一些配置参数
- 常见配置:
- mapred.map.tasks: map task数目
- mapred.reduce.tasks : reduce task数目
- stream.num.map.putput.key.fields:制定map task 输出记录中key所占的域数目
- num.key,fields.for.partition制定对key分出来的前几部分做partition,而不是整个key
- 常见配置:
- 配置参数
- mapred.job.name 作业名
- mapred.job.priority 作业优先级
- mapred.job.map.capacity 最多同时运行mapduce任务数
- mapred.task.timeout 任务没有响应(输入输出)的最大时间
- mapred.compress.map.output map的输出是否压缩
- mapred.map.output.compression.codec map的输出压缩方式
- mapred.output.compress reduce的输出是否压缩
- mapred.output.compression.codec reduce的输出压缩方式
- stream.map.output.field.separator map输出分隔符
实例一 文件分发与打包
- 执行脚本
run.sh1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH_1="/The_Man_of_Property.txt"
OUTPUT_PATH="/output_file_broadcast"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func white_list" \
-reducer "python red.py reduer_func" \
-jobconf "mapred.reduce.tasks=3" \
-file ./map.py \
-file ./red.py \
-file ./white_list
#$HADOOP_CMD jar $STREAM_JAR_PATH -input $INPUT_FILE_PATH_1 -output $OUTPUT_PATH -mapper "python map.py mapper_func white_list" -reducer "python red.py reduer_func" -jobconf "mapred.reduce.tasks=3" -file ./map.py -file ./red.py -file ./white_list1
2
3
4
5
6
7cat The_Man_of_Property.txt | grep -o --color against | wc -l
bash run.sh
### 任务缓存目录: /usr/local/src/hadoop-1.2.1/tmp/mapred/local/taskTracker/root/jobcache/job_201712301253_0001/attempt_201712301253_0001_m_000001_0/work
### 任务完成以后会被删除
[root@slave2 work]# ls
job.jar map.py META-INF org red.py tmp white_list - 如果要分发的文件在本地且没有目录结构,可以使用
-f /path/to/FileName选项分发文件,将本地文件/path/to/FilenName分发到每个计算节点 - 在Streaming程序中通过
./FileName就可以访问该文件 - 对于本地可执行文件,处理指定的mapper或reducer程序外,可能分发后没有可执行权限,所以需要在包装程序如mapper.sh中运行chmod + x ./FileName设置可执行权限,让后设置-mapper
mapper.sh
实例二 : 文件分发与打包
- 如果文件存放在HDFS,希望计算时在每个计算节点上将文件当做本地文件处理,可以使用
-cacheFile - streaming程序通过
./linkname访问文件 -cacheFile "hdfs://host:port/path/to/file#linkname"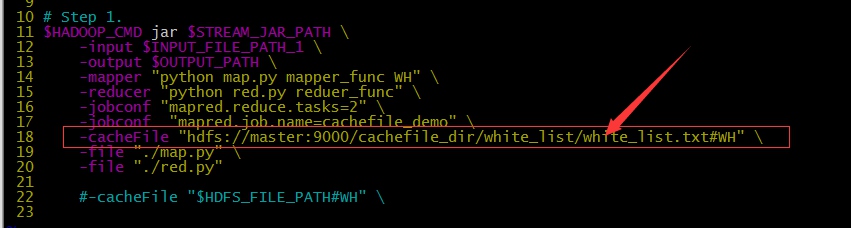
实例三: 文件分发与打包
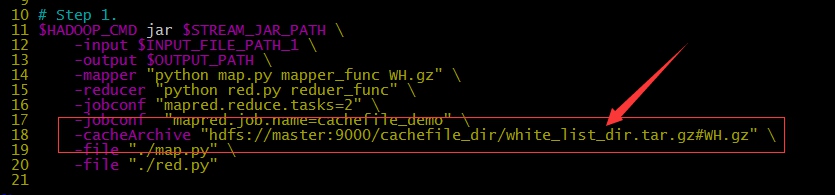
- cacheArchive
- 如果要分发的文件有目录结构,可以先将整个目录打包,让后上传到HDFS,再用
-cacheArchive "hdfs://host:port/path/to/archivefile#linkname"分发压缩包
实例四: 输出数据压缩
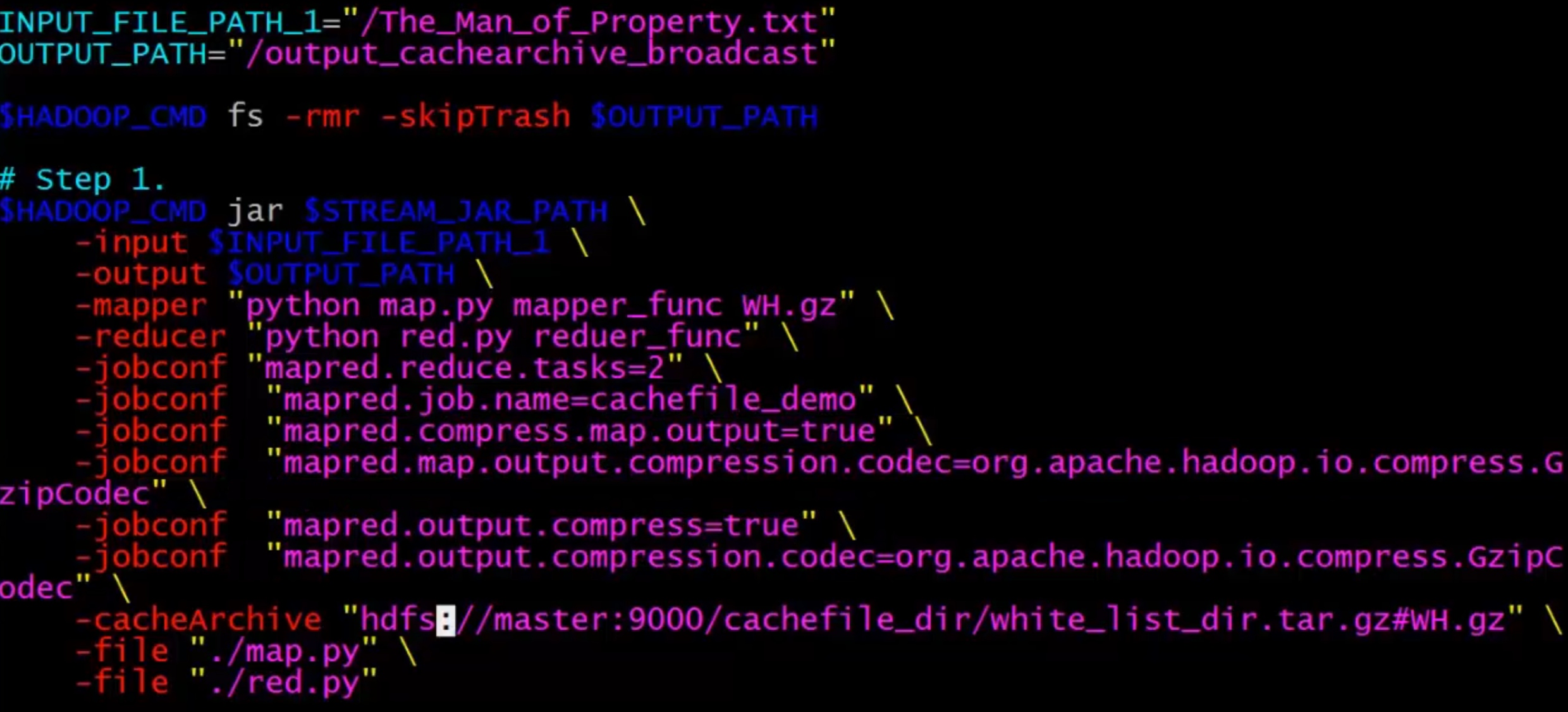
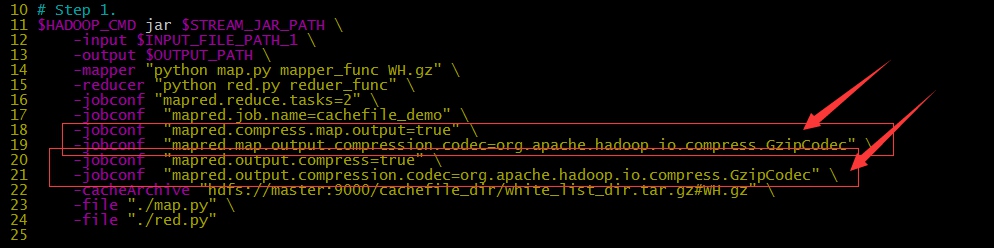
- 输出数据量较大时,可以使用Haddop提供的压缩机制对数据进行压缩,减少网络传输带宽和内存的消耗
- 可以指定对map的输出也就是中间结果进行压缩
- 可以指定对reduce的输出也就是最终输出进行压缩
- 可以指定是否压缩以及采用哪种压缩方式
- 对map输出进行压缩主要是为了减少shuffle过程中网络传输数据量
- 对reduce输出进行压缩主要是减少输出结果占用的HDFS存储
- 指定压缩参数
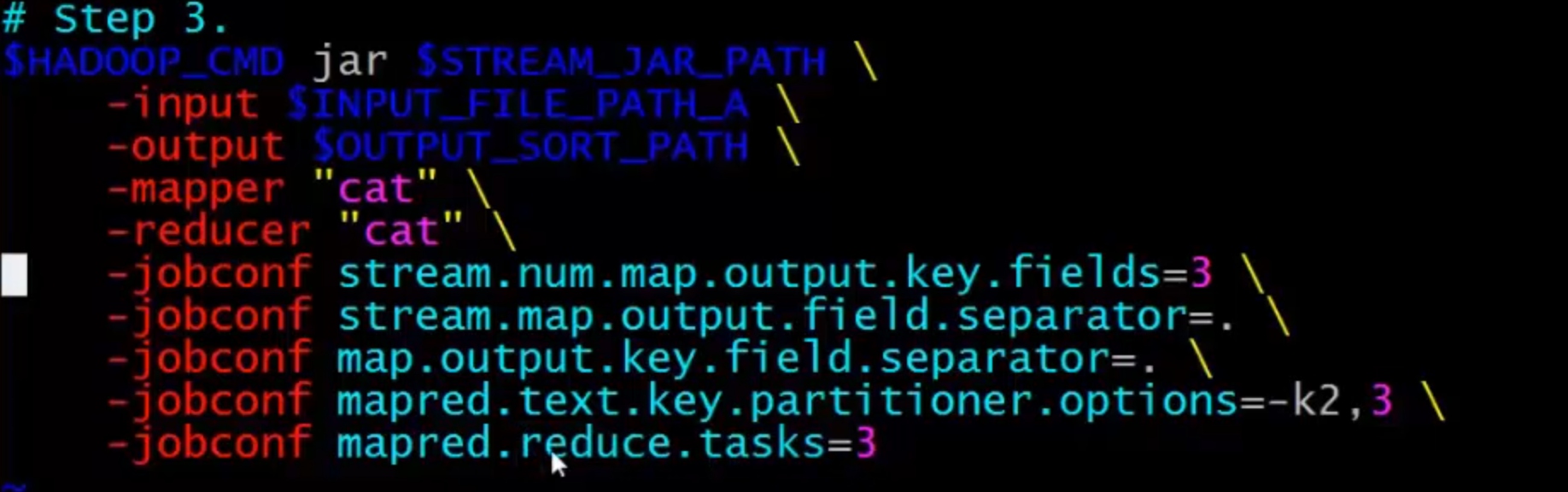
实例五: 全局排序
- 单reduce
- 多reduce
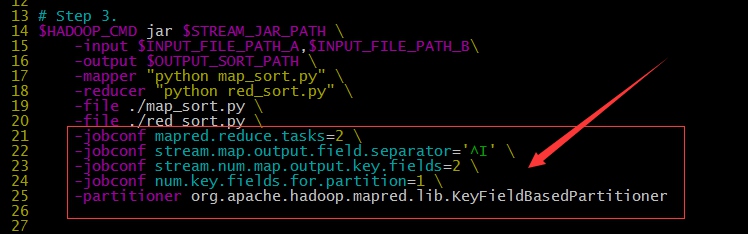
- 全局排序: 设置排序/分桶存储
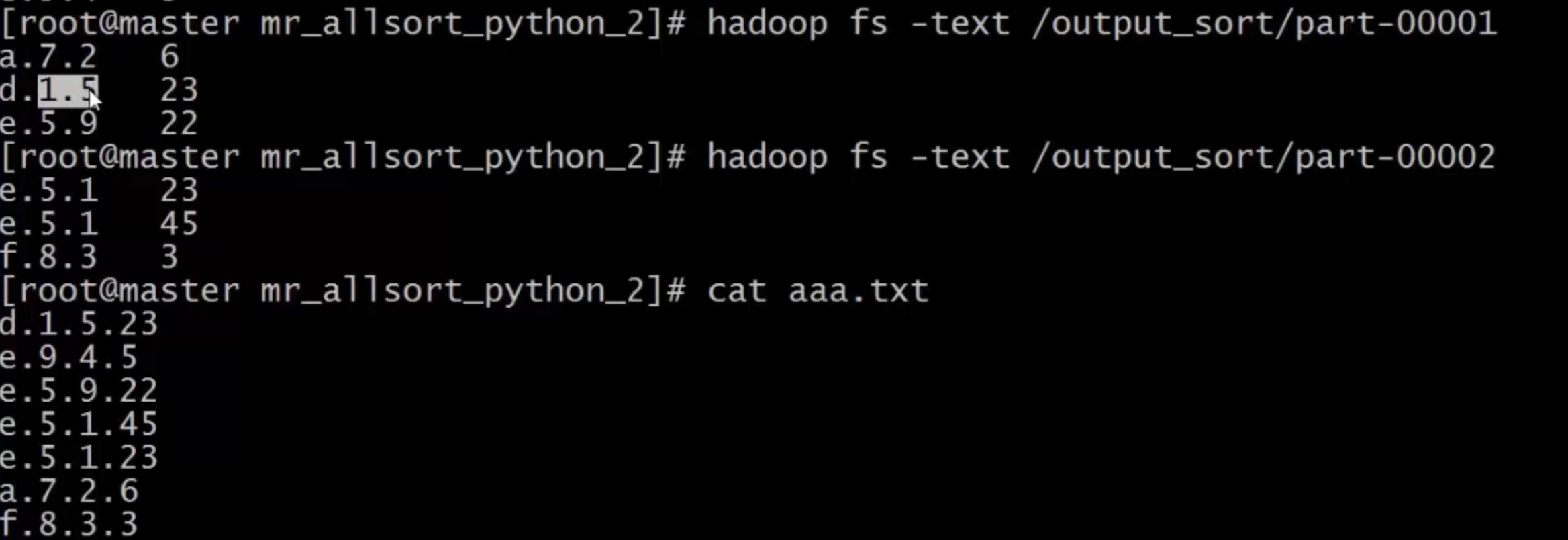
- 输出结果
实例六: 表单jonin
- 数据拼合
- 将两个文件,模拟成两份数据表,按key进行join
实例七: 与算法结合
- 二分查找、区间查找、折半查找,属于有序查找算法
- 元素必须有序,如果无需,则要先进性排序操作
- ip定位
实战总结

数据过滤
- 产检应用
- 从日志中找到某一条件(时间,用户)数据
- 除非非法数据,保留合法数据
- 数据格式整理
- 模型抽象
- 从大数据中,选择满足条件的数据并输出
- 产检应用
同类汇聚
- map join
- 多分日志中,相同时间点、用户行为日志混合一起
- 类表格文件存储中,相同主键拼接相关属性
- 历史的主要数据与新增,修改数据合并
- 模型抽象:
- 两份、多份数据中,使用相关的key合并、拼接对应的数据并输出
全局排序
- 混合日志,按时间排列好顺序
- 按某个或多个字段排序
- 抽象
- 大量数据、日志中,存在一个序列,最终安序列有序输出
容错框架
- 易出错的服务, 724365
- 计算规模经常变化调整的服务
- 单进程程序,迅速提升执行计算效率
- 模型抽象
- 简单服务扩展

