Storm
Storm
AlexStorm
实时数据分析需求
- 实时报表动态展现
- 数据流量波动状态
- 反馈系统
时效性
- 秒级处理完成数据
- Storm可以做到毫秒级
增量式处理
- 数据来一条,处理一条
开源分布式实时计算系统
Twitter出品
托管在github上
目前互联网中应用最广泛
- 相对稳定,有高容错性
- 开源
没有持久化
保证消息得到处理
支持支持多种编程语言
高效,用ZeroMq作底层消息处理
支持本地模式,可模拟集群所有功能
使用原语
- 类同MapReduce中的Map、Reduce
流式处理
- 时效性高
- 逐条处理数据
- 低延时
- 不是一个新概念
- 管道(PIPE)
- cat input |grep pattern | sort | uniq > output
- cat input | python map.py | sort | python reduce.py > outpu
分布式流处理
- 单机处理不了
- 内存
- cpu
- 存储
- 多机流失系统
- 流量控制
- 容灾荣余
- 路径选择
- 扩展
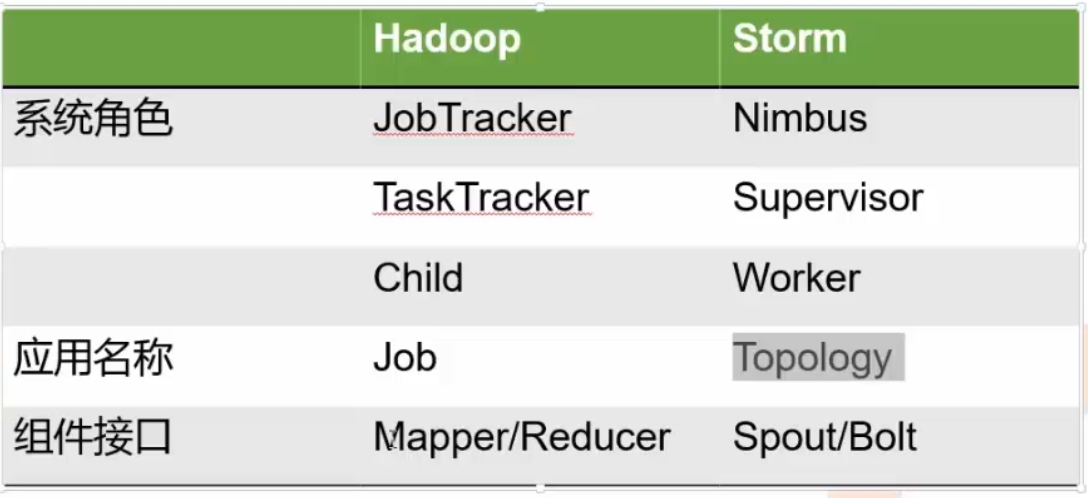
Storm vs Hadoop
- Storm任务没有结束,Hadoop任务执行完结束
- Storm延时更低,得益于网络直传、内存计算,省去了批处理的收集数据的时间
- Hadoop使用磁盘作为中间交换的介质,而storm的数据是一直在内存中流转的
- Storm的吞吐能力不及Hadoop,所以不适合批处理计算模型
- 延时,指数据从产生到运算产生结果的时间
- 吞吐,指系统单位时间处理的数据量
基本概念
- Stream
- 以Tuple为基本单位组成的一条有向无界的数据流
- Tuple
- Integer,long,short,byte,string,double,float,boolean和byte array,包括自定义类型
- Topology
- 计算逻辑的封装
- 由spouts和bolts组成的图,通过stream grouping将图中的spouts和bolts连接起来
- 类同MapReduce中的job
- 不会结束,除非主动kill
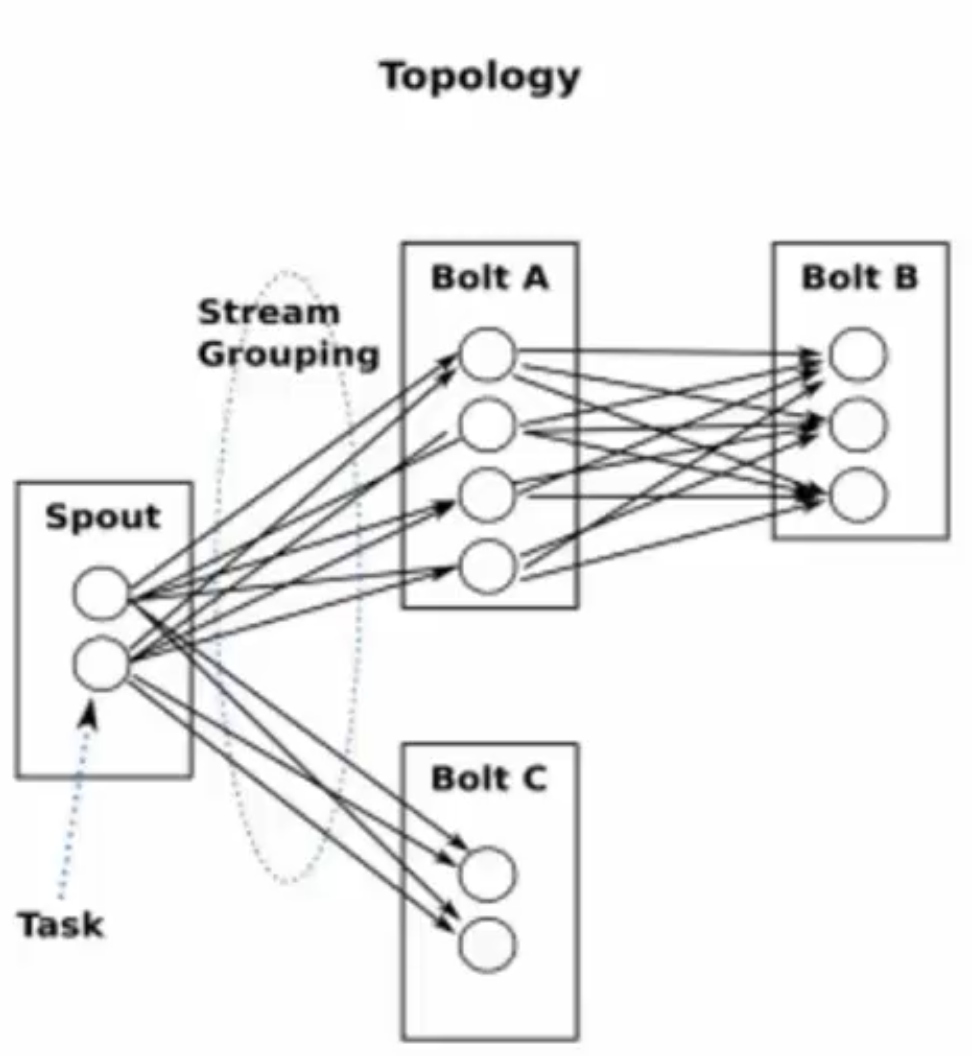
- Topology任务执行
- Storm jar code.jar MyTopologyarg1 arg2
- storm jar负责连接到Nimbus并且上传jar包
- 运行主类MyTopology, 参数是arg1, arg2;这个类的main函数定义这个topology并且把它提交给Nimbus
- Topology的定义是一个Thrift结构,并且Nimbus就是一个Thrift服务,你可以提交由任何语言创建的topology
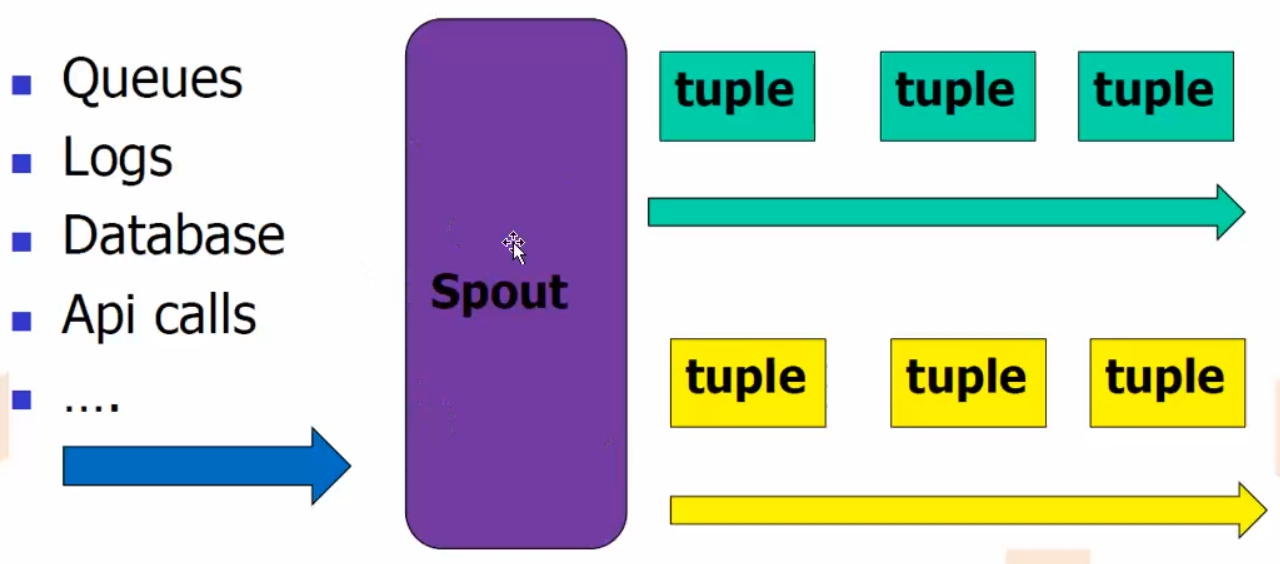
Spout
- 消息来源,消息生产者
- 可靠的,不可靠的
- 可靠的,如果没有被成功处理,可重新emit一个tuple
- 可指定emit多个Stream流
- OutFieldsDeclarer.declareStream定义
- SpoutOutputCollector指定
- nextTuple
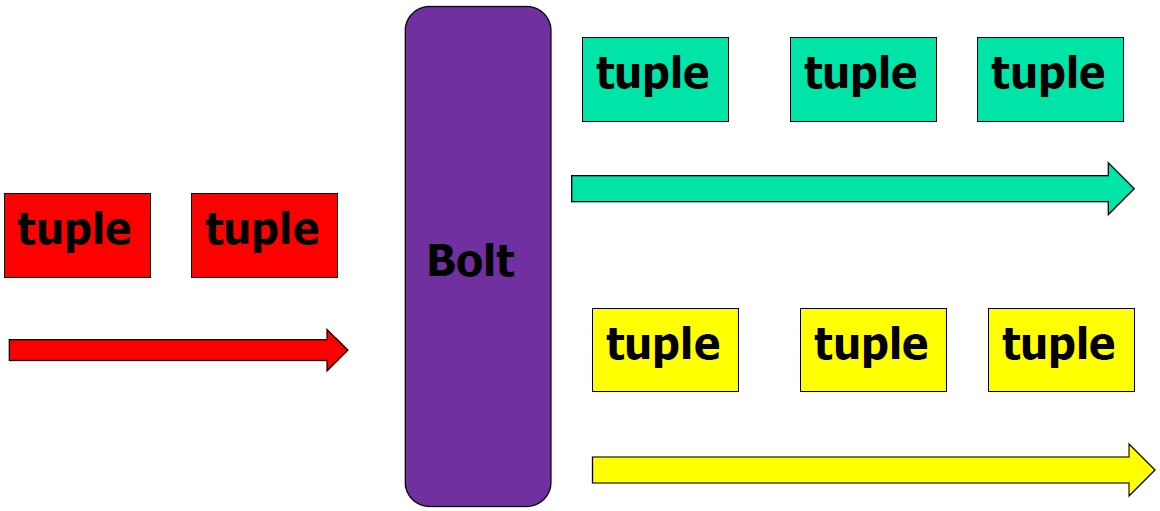
- Bolt
- 消息处理逻辑
- 如过滤,访问数据库,聚合
- 多个bolt处理负责步骤
- 可以发射多个数据流
- 主方法为execute
- 以tuple为输入
- 处理具体的tuple
- 发射0或多个tuple
- OutputCollector的ack,确认
- IBasicBolt,会自动调节
- 消息处理逻辑

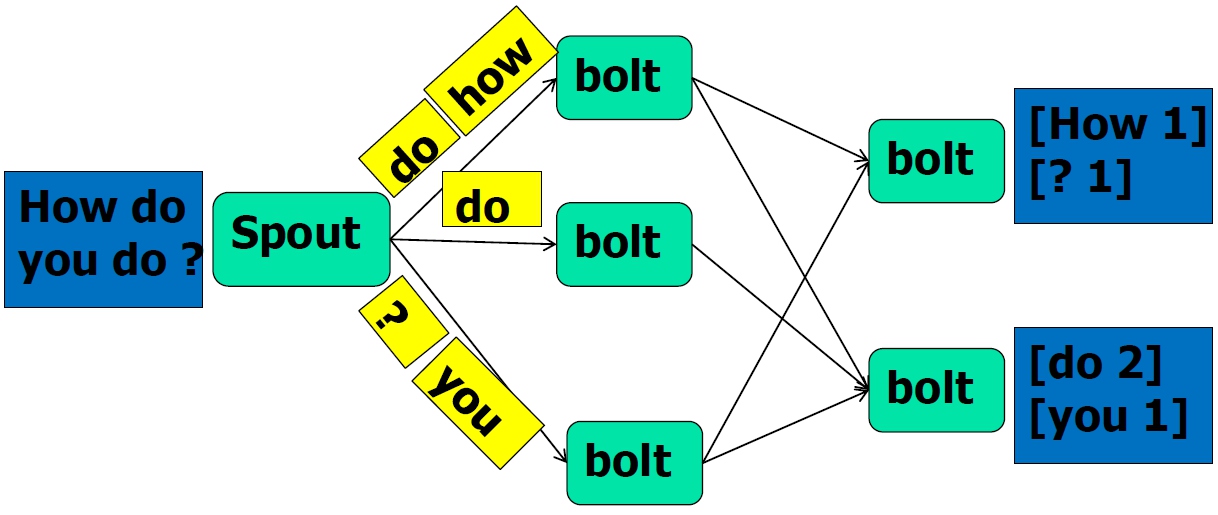
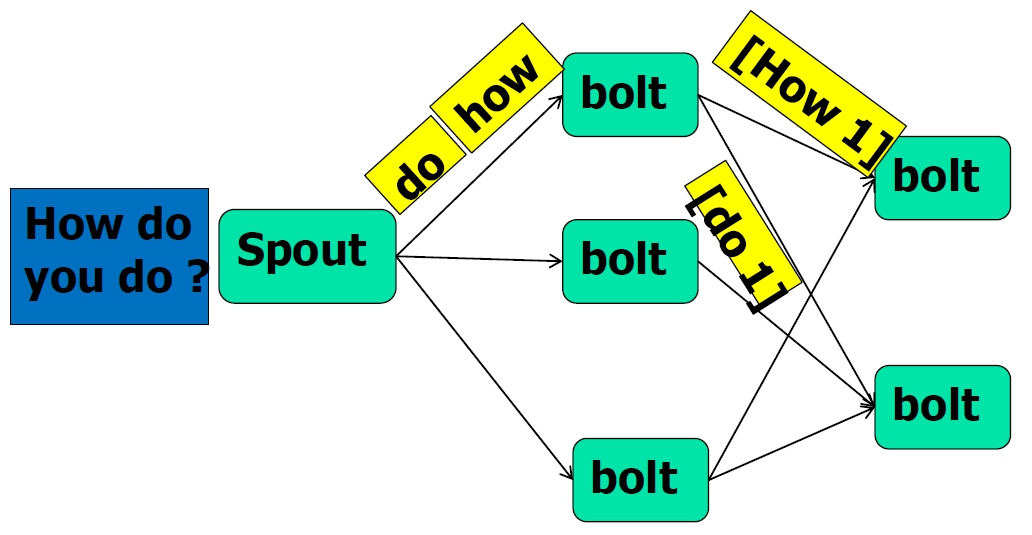
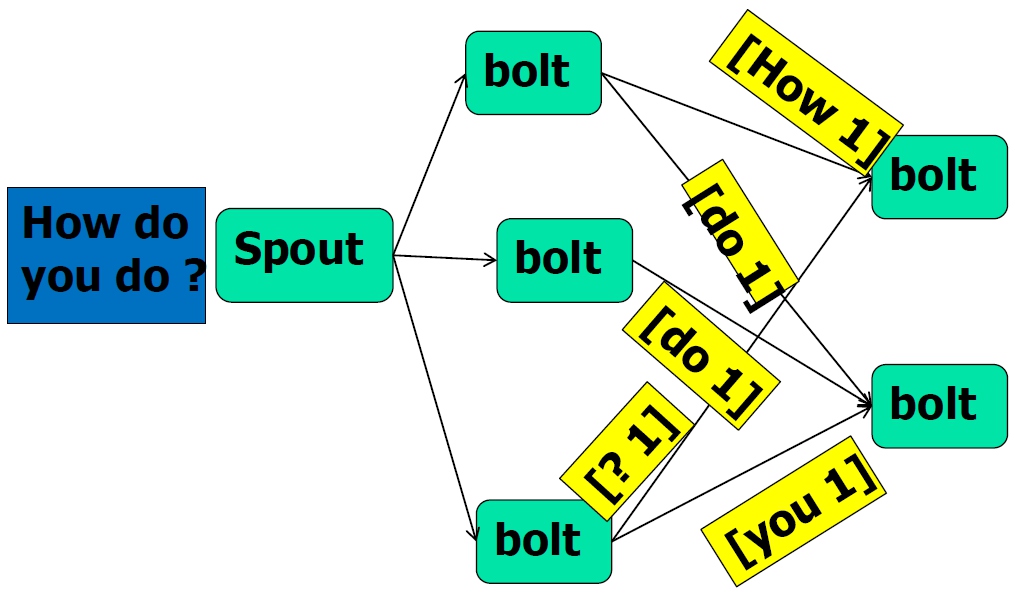
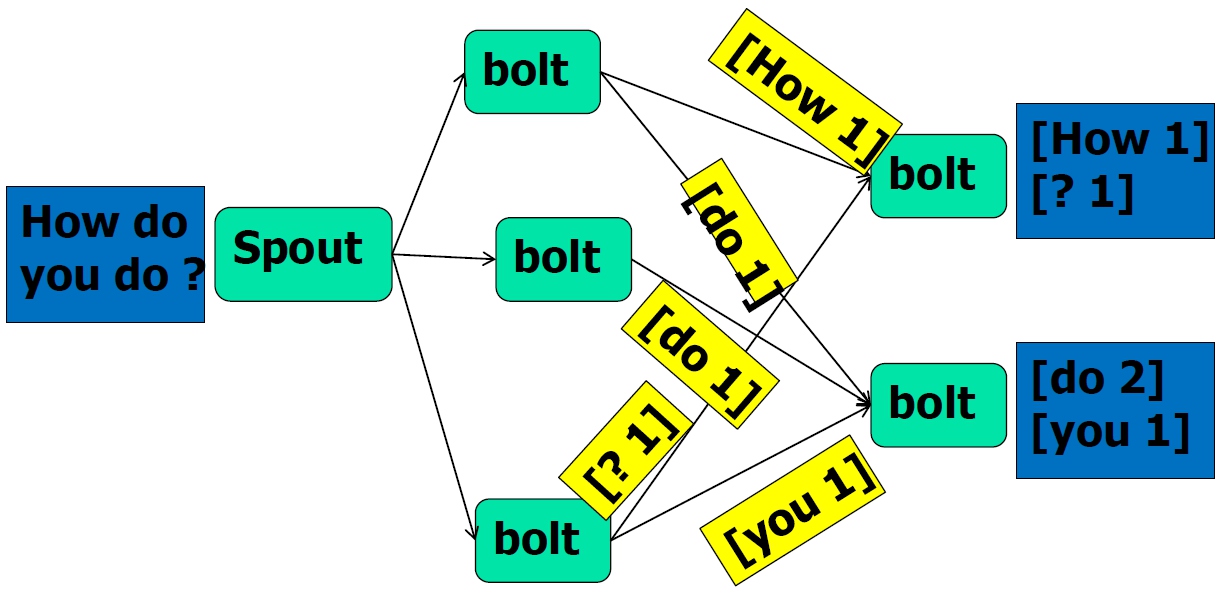
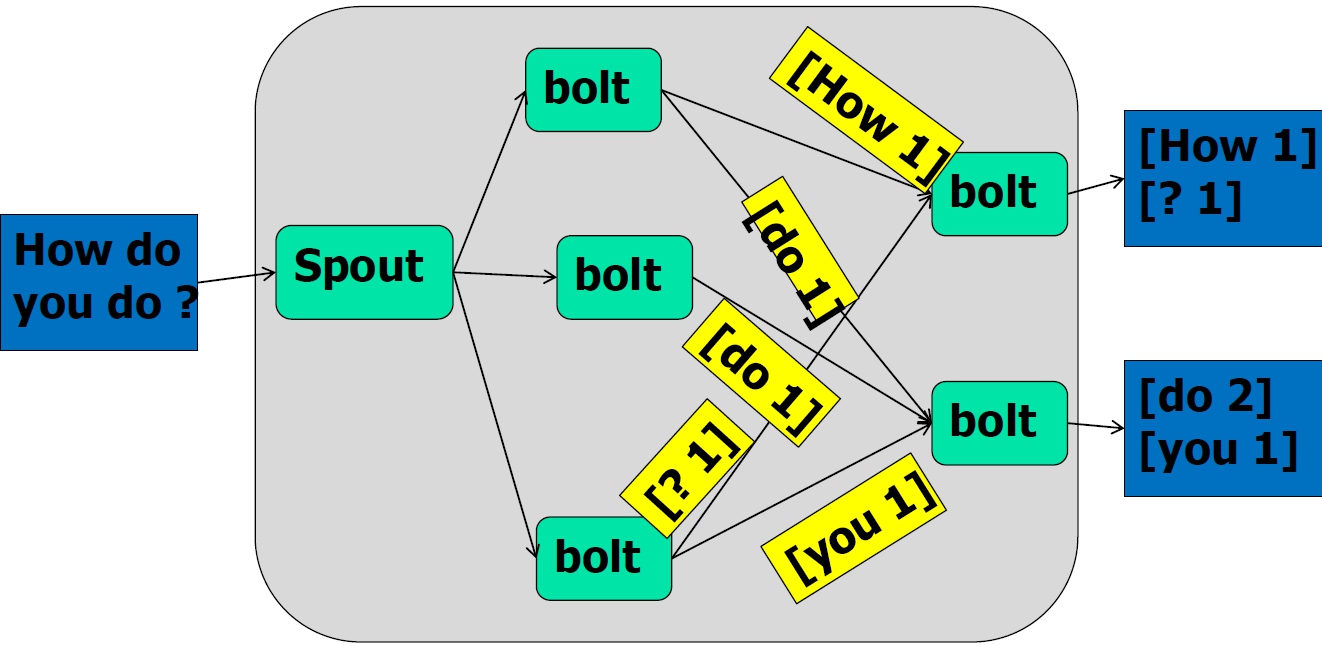
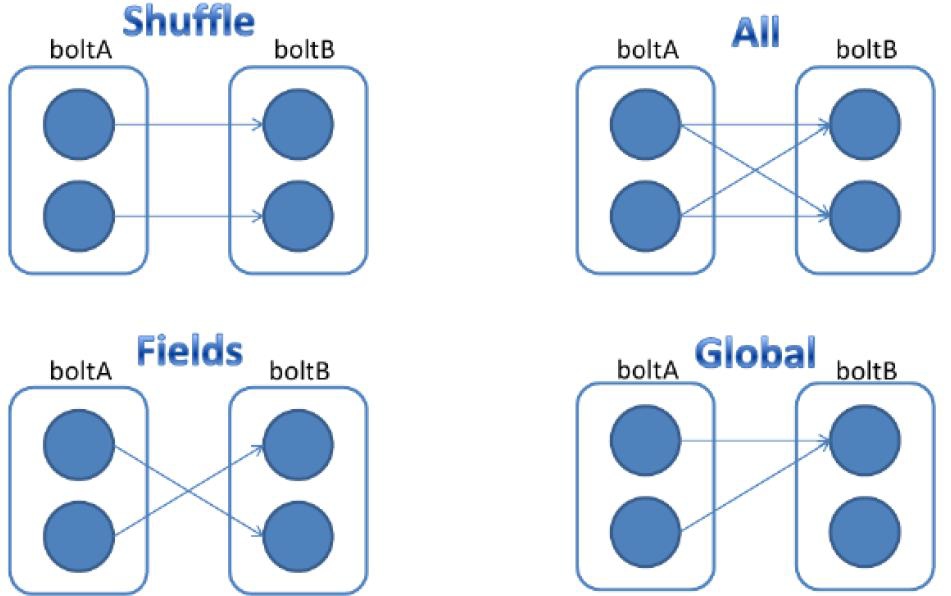
- Stream Grouping
- Shuffle Grouping:随机分组
- Fields Grouping:按指定的field分组
- All Grouping:广播分组
- Global Grouping:全局分组
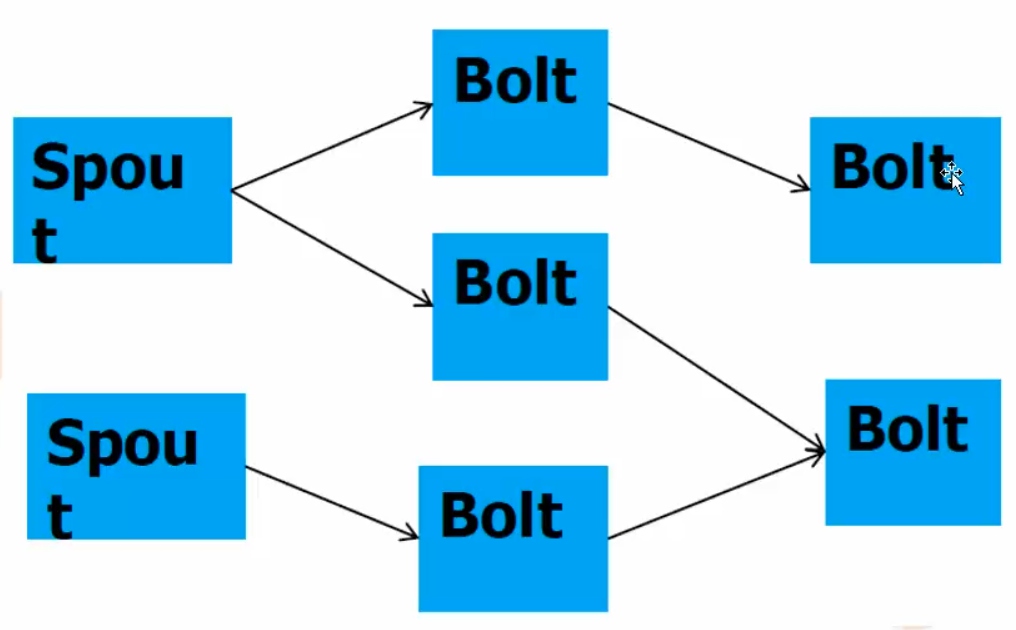
常规模式
- 流失计算
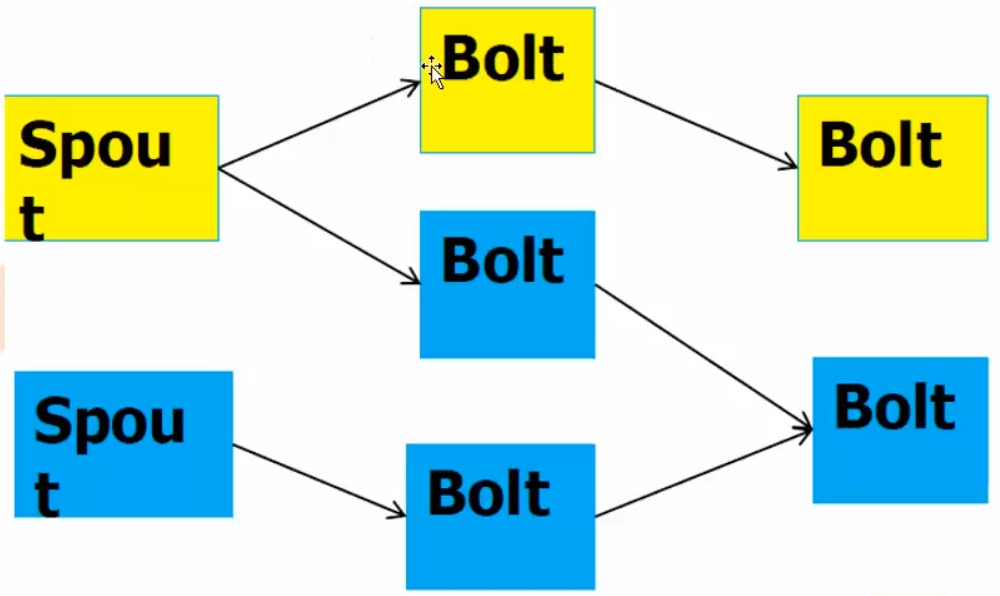
- 流失模式 - 过滤、组装
- 组装记录log日志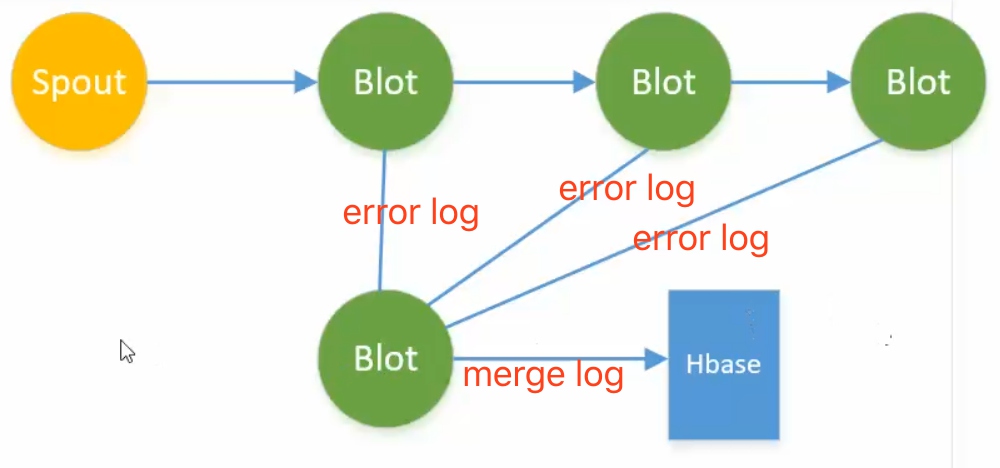
- 流式模式 - join
- 某时间段内join
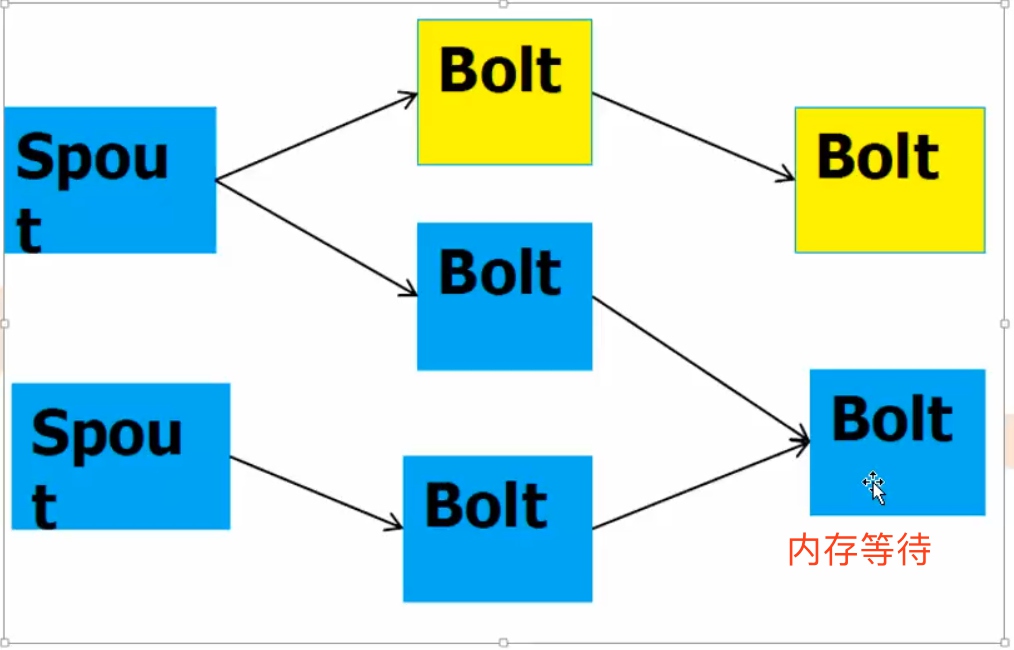
- 流式模式 - 分布式RPC
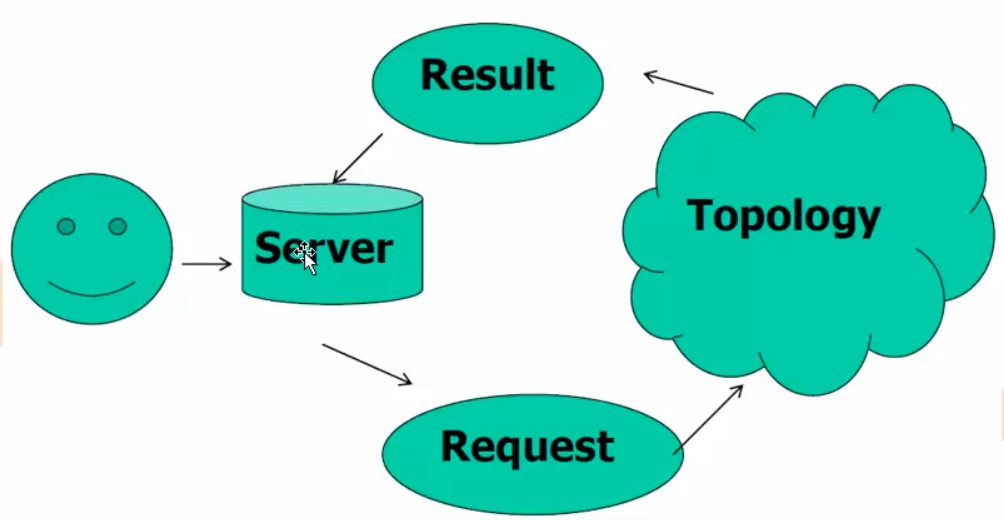
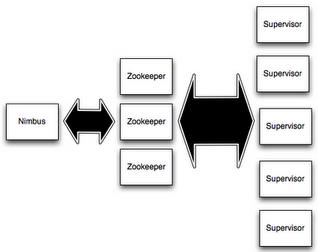
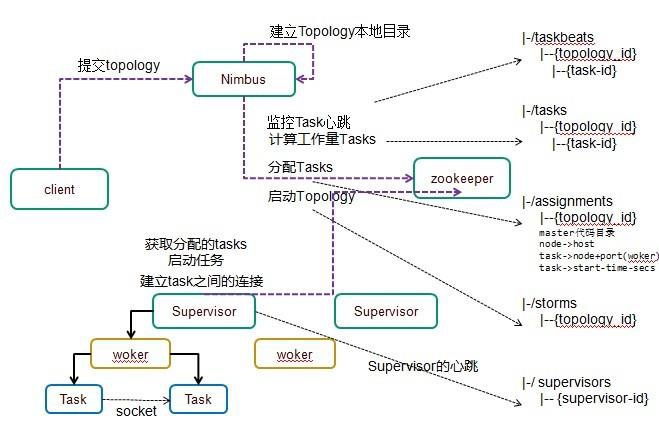
storm架构
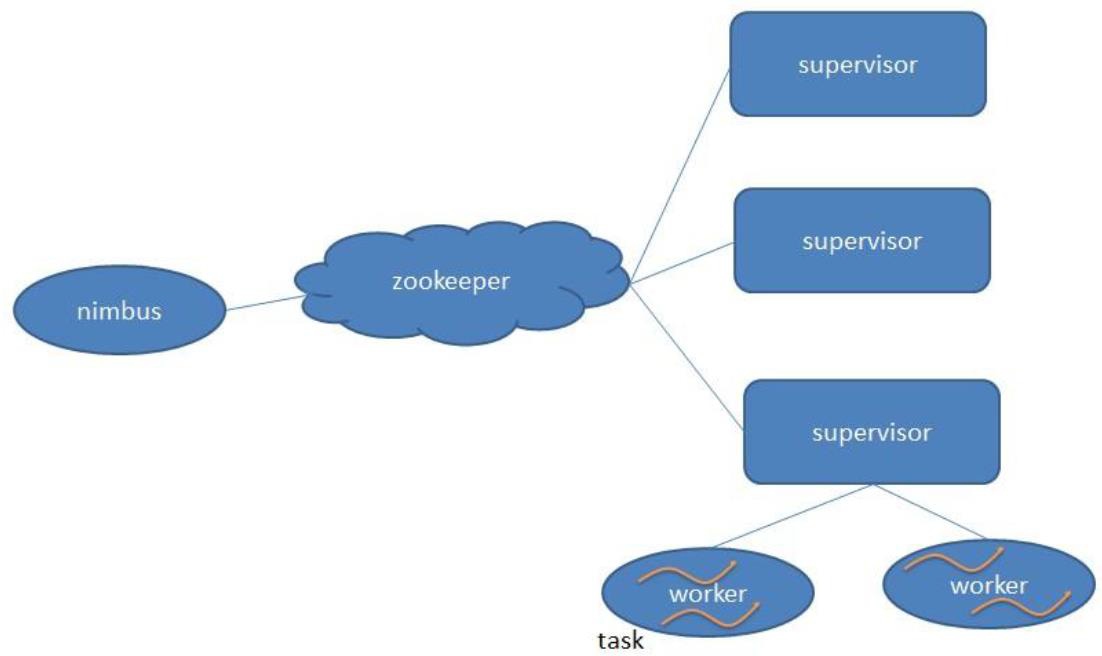
- storm分为主、从
- 主:用来资源分配和任务调度
- 从:接收nimbus分配任务
- 通过zookeeper管理supervisor
- 同一个spout、bolt共享一个物理线程
- strom最小的粒度task
- spout、bolt线程 -> task
- 多个task共享一个excutor线程
- 在一个executor线程上,会执行很多task
- 标准的来说, executor是线程 ,task是executor处理一个或多个任务,那么这个任务就是spout或者bolt
- 所以task本质就是一个节点类的实例对象
- set_num_task 来配置一个executor同时和处理多个task,默认一个excutor执行一个task
- work是进程,work里面有多个executor
Nimbus
- Master Node
- 负责资源分配和任务调度
- 类似Hadoop里的JobTracker,负责在集群里面分发代码,分配计算任务给Supervisor,并且监控状态
Supervisor
Worker Node
负责接收nimbus分配的任务
每个工作节点存在一个
启动和停止属于自己管理的worker进程(每一个工作进程执行一个Topology的一个子集,一个Topology由运行在很多机器上的很多worker工作进程组成)
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成
Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有状态要么在Zookeeper里面,要么在本地磁盘上
这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程,然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
Worker
- 运行具体处理组件逻辑的进程
- 一个Topology可能会在一个或者多个worker里面执行
- 每个worker是一个物理JVM并且执行整个Topology的一部分
- 采取JDK的Executor
比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks,Storm会尽量均匀的工作分配给所有的worker
Task
- Worker中的每一个spout/bolt的线程称为一个task
- 每一个spout和bolt会被当作很多task在整个集群里执行
- 每一个executor对应到一个线程,在这个线程上运行多个task
- stream grouping则是定义怎么从一堆task发射tuple到另外一堆task
- 可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)
Worker 与 Task关系
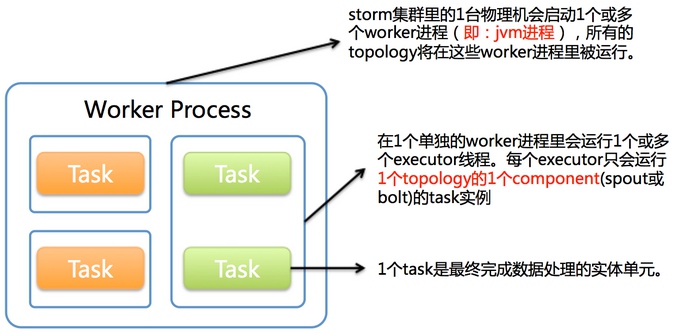
- 1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
- executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
- task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
1 | Configconf= new Config(); |
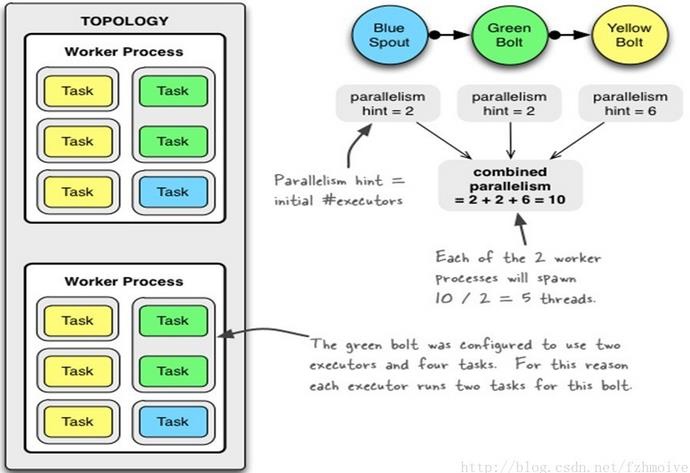
- 重新配置Topology “myTopology”使用5个Workers
- BlueSpout使用3个Executors
- YellowSpout使用10个Executors
- storm rebalance myTopology-n 5 -e BlueSpout=3 -e YellowSpout=10
- 总结:一个topology可以通过setNumWorkers来设置worker的数量,通过设置parallelism来规定executor的数量(一个component(spout/bolt)可以由多个executor来执行),通过setNumTasks来设置每个executor跑多少个task(默认为一对一)。
task是spout和bolt执行的最小单元。
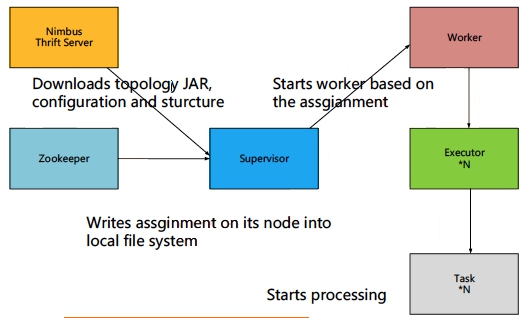
Storm容错 - 架构容错
- Zookeeper
- 存储Nimbus月Supervisor数据
- 节点宕机
- Heartbeat
- worker来汇报 – executor
- Supervisor来汇报 – 自己状态
- Nimbus
- Heartbeat
- Nimbus/Supervisor宕机
- Worker继续工作
- Worker失败,任务失败
- Worker出错
- Supervisor重启Worker
Storm容错 - 数据容错
- Storm的可靠性是指Storm会告知用户每一个消息单元是否在一个指定的时间(timeout)内被完全处理。
- Ack机制(Storm中的每一个Topology中都包含有一个Acker组件)
- 所有的节点ack成功,任务成功
- ack的本质是一个或多个task,特殊的task,而且非常轻量
- 工作:反馈信息和传递
特殊的Task(Acker Bolt)
- Acker,跟踪每一个spout发出的tuple树
- 一个tuple树完成时,发送消息给tuple的创造者
- Acker的数量,默认值是1
- 如果你的topology里面的tuple比较多的话,那么把acker的数量设置多一点,效率会高一点。

实现
- 内存超级大
- Acker Task并不显式的跟踪tuple树。对于那些有成千上万个节点的tuple树,把这么多的tuple信息都跟踪起来会耗费太多的内存。
真实实现
- 内存量是恒定的(20bytes)
- 对于100万tuple,也才20M 左右
- Taskid:ackval
- Ackval所有创建的tupleid/ack的tuple一起异或
- 一个acker task存储了一个spout-tuple-id到一对值的一个mapping。这个对子的第一个值是创建这个tuple的taskid,这个是用来在完成处理tuple的时候发送消息用的。第二个值是一个64位的数字称作:ackval, ackval是整个tuple树的状态的一个表示,不管这棵树多大。它只是简单地把这棵树上的所有创建的tupleid/ack的tupleid一起异或(XOR)。
Storm环境
wgethttp://www.python.org/ftp/python/2.6.6/Python-2.6.6.tar.bz2
Conf/storm.yaml
storm.zookeeper.servers
- 多个Zookeeper服务器
Storm.local.dir
- Storm用于存储jar包和临时文件的本地存储目录
Java.library.path
Nimbus.host
Supervisor.slots.ports
- 几个port,就几个worker
Ui.port
bin/storm nimbus >/dev/null 2>&1 &
bin/storm supervisor >/dev/null 2>&1 &
bin/storm ui>/dev/null 2>&1 &
http://{nimbus host}:port
./logs
查看错误日志
