Zookeeper
Zookeeper
AlexZookeeper
分布式系统的问题
- 与单机系统不同
- 内存地址一致
- 单机出问题概率低 - 分布式系统
- 一致性问题
- 容灾容错
- 执行顺序问题
- 事务性问题
- 核心问题
- 没有一个全局的主控,协调或控制中心
- 单机不可靠
- 环中有环
- 特殊场景下,特殊实现,但不通用
- 我们需要什么?
- 一个松散耦合的分布式系统中粗粒度锁以及可靠性存储(低容量)的系统
- 没有一个全局的主控,协调或控制中心
zookeeper
- Hadoop系统
- 开源的,高效的,可靠的协同工作系统
- 名字服务器,分布式同步,组服务
- Google内部实现叫Chubby
- 基于Paxos协议
zookeeper概述
- 数据模型
- 命名空间
- 与标准文件系统很相似
- 以/ 为间隔的路径名序列组成
- 只有绝对路径,没有相对路径
- 每个节点自身的信息
- 数据
- 数据长度
- 创建时间
- 修改时间
- 具有文件,路径的双重特点
zookeeper结构
1 | / |
Persistent Nodes
- –永久有效地节点,除非client显式的删除,否则一直存在
Ephemeral Nodes
- –临时节点,仅在创建该节点client保持连接期间有效,一旦连接丢失,zookeeper会自动删除该节点
Sequence Nodes
- 顺序节点,client申请创建该节点时,zk会自动在节点路径末尾添加递增序号,这种类型是实现分布式锁,分布式queue等特殊功能的关键
监控机制(watch)
- 数据节点上设置
- 客户端被动收到通知
- 各种读请求,如getData(),getChildren(),和exists()
三个关键点
- 一次性监控,触发后,需要重新设置
- 保证先收到事件,再收到数据修改的信息
- 传递性
- 如create会触发节点数据监控点,同时也会触发父节点的监控点
- 如delete会触发节点数据监控点,同时也会触发父节点的监控点
风险
- 客户端有可能看不到所有数据的变化
- 多个事件的监控,有可能只会触发一次
- 一个客户端设置了关于某个数据点exists和getData的监控,则当该数据被删除的时候,只会触发“文件被删除”的通知。
- 客户端网络中断的过程的无法收到监控的窗口时间,要由模块进行容错设计
数据访问
- 每个节点上的“访问控制链”(ACL, Access Control List)保存了各客户端对于该节点的访问权限。
- 用一个三元组来定义客户端的访问权限:(scheme:expression, perms)
- ip:19.22.0.0/16, READ)表示IP地址以19.22开头的主机有该数据节点的读权限。
数据访问
| 权限 | 描述 | 备注 |
|---|---|---|
| CREATE | 有创建子节点的权限 | |
| READ | 有读取节点数据和子节点列表的权限 | |
| WRITE | 有修改节点数据的权限 | 无创建和删除子节点的权限 |
| DELETE | 有删除子节点的权限 | |
| ADMIN | 有设置节点权限的权限 |
- zookeeper本身提供了ACL机制,表示为scheme:id:permissions,第一个字段表示采用哪一种机制,第二个id表示用户,permissions表示相关权限(如只读,读写,管理等)
|模式|描述 |
| — | —| —|
|World |它下面只有一个id, 叫anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就是属于world:anyone的 | |
|Auth | 已经被认证的用户 | |
| Digest | 通过username:password字符串的MD5编码认证用户 | |
|Host |匹配主机名后缀,如,host:corp.com匹配host:host1.corp.com, host:host2.corp.com,但不能匹配host:host1.store.com | |
|IP | 通过IP识别用户,表达式格式为addr/bits | |
- 一致性保证
- 序列一致性:客户端发送的更新将按序在Zookeeper进行更新
- 原子一致性:更新只能成功或者失败,没有中间状态
- 单系统镜像:无论连接哪台Zookeeper服务器,客户端看到的服务器数据一致
- 可靠性:任何一个更新成功后都会持续生效,直到另一个更新将它覆盖。可靠性有两个关键点: 第一,当客户端的更新得到成功的返回值时,可以保证更新已经生效,但在某些异常情况下(超时,连接失败),客户端无法知道更新是否成功;第二,当更新成功后,不会回滚到以前的状态,即使是在服务器失效重启之后
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口
应用场景
- 配置管理
- 全局的系统配置
- 容错并且统一
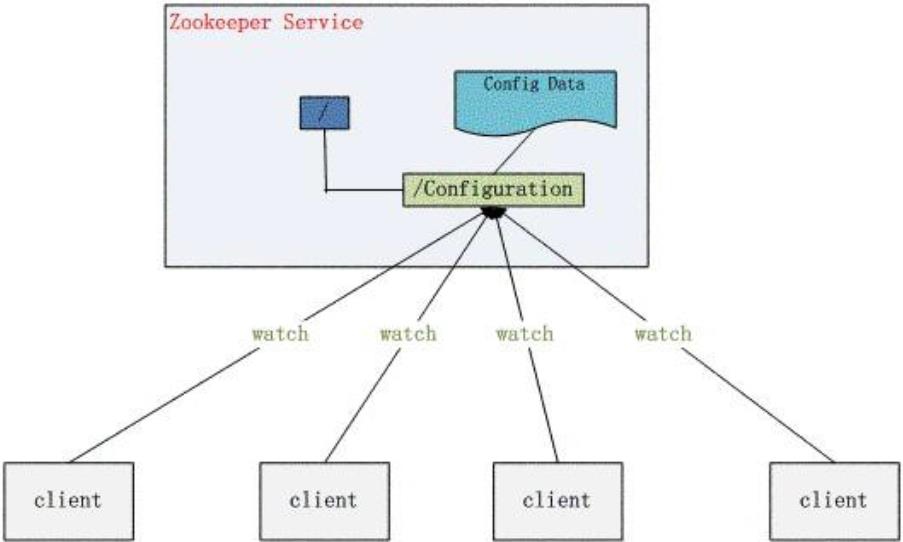
集群管理(Group Membership)
- 了解每台服务器的状态
- 新增删除服务,需要周知
- 选择一个主服务器
集群管理(Group Membership)-集群状态
- EPHEMERAL节点
- 所有的server getChildren(String path, booleanwatch) 方法
- 某台服务器下线,对应的节点自动删除
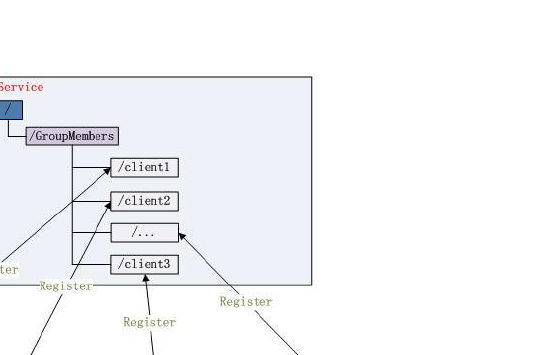
- 集群管理(Group Membership)-选主节点
- EPHEMERAL_SEQUENTIAL
- 选择当前是最小编号的Server 为Master
- 最小编号的Server 死去,由于是EPHEMERAL节点,死去的Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点
- 共享锁(Locks)
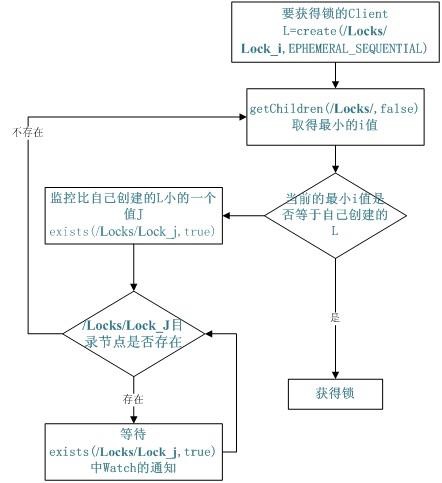
- 队列管理
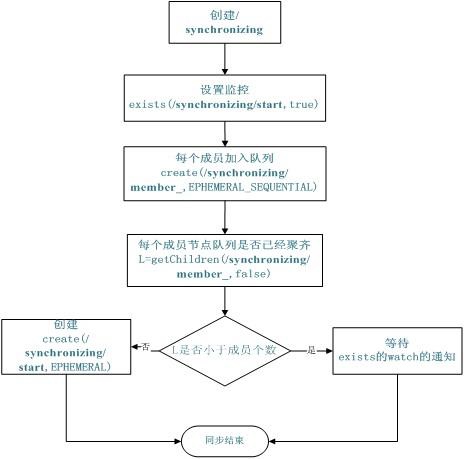
- 同步队列
- 所有成员都聚齐才可使用
- 同步队列
- FIFO队列
- 生产消费者
- 创建SEQUENTIAL 类型的子目录/queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过getChildren( ) 方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证FIFO。
Zookeeper使用
- 运行命令
1
2
3
4zkServer.sh start
zkServer.sh status
zkServer.sh stop
zkCli.sh -server zookeeper:2181 - 执行客户端zkCli.sh
- ls / 查看当前目录
- create /text “test” 创建节点
- create -e /text “test” 创建临时节点
- create -s /text “test” 创建序列节点
- get /test 查看节点
